
Most companies still think the main problem with AI is model quality. It isn’t.
For the last year, the AI market has been obsessed with models.
Every few months, a new release resets the conversation: better reasoning, longer context windows, stronger benchmarks, more agentic behavior. Teams switch from one model to another hoping the next upgrade will finally make their AI systems reliable.
But here’s the uncomfortable reality:
The intelligence of an AI agent is becoming a commodity.
The context it operates on is the moat.
You can’t solve a data meaning problem with a reasoning upgrade.
The model is the engine. Context is the fuel. Most companies are just swapping engines while pouring the wrong fuel into the tank.
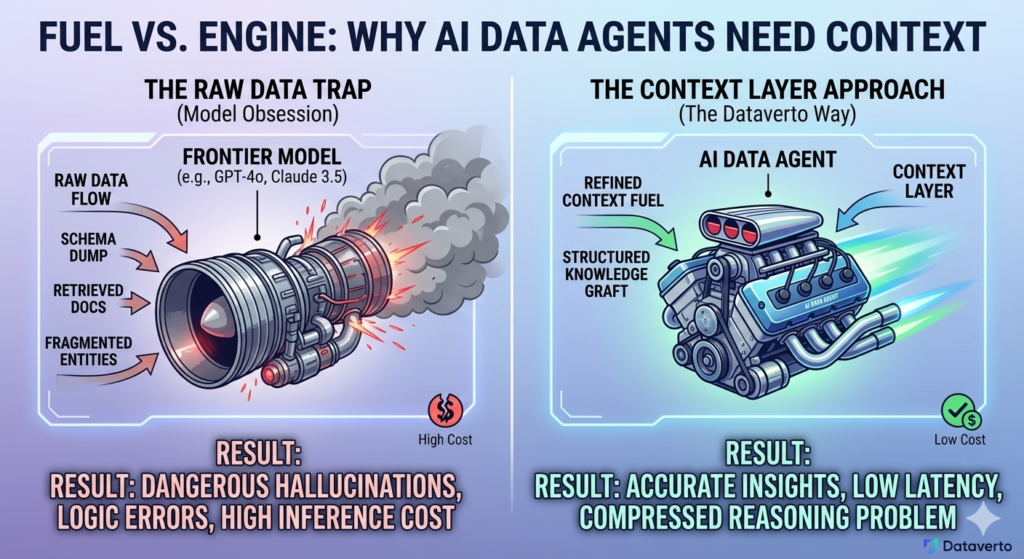
A stronger model can reason better. But it cannot reason correctly over missing definitions, fragmented entities, inconsistent metrics, or raw data with no semantic structure.
That is why so many AI agents look impressive in demos — and unreliable in production.
The future of AI in data is not better models. It is better context systems.
TL;DR
- Model intelligence is becoming commoditized — advantage shifts to context engineering.
- Traditional RAG fails on structured data because it lacks semantic grounding.
- A Context Layer encodes entities, metrics, and relationships.
- Strong context reduces inference cost while increasing accuracy.
Why better models are not enough
There is a persistent belief in the market that unreliability is a model problem — that the next release will fix it.
But most real-world failures of AI data agents are not reasoning failures. They are context failures.
A data agent doesn’t break because it can’t write SQL. It breaks because it uses the wrong definition of revenue, queries a deprecated table, or confuses margin with top-line growth. The output can look perfectly coherent and still be wrong in every way that matters to the business.
Smarter models don’t fix missing business meaning. They just fail more convincingly.
At a certain point, intelligence stops being the bottleneck.
Context becomes the bottleneck.
The model is the engine. Context is the fuel
An AI data agent is not just a model — it’s a system that transforms questions into decisions.
The model performs reasoning. The context determines whether that reasoning is grounded in reality.
Most systems today give models access to data, but not to meaning. A schema dump, a few table descriptions, and some retrieved documentation might be enough to generate a query, but they are not enough to understand a business.
A human analyst would never operate like this. They bring definitions, historical knowledge, edge cases, and a sense of what can and cannot be trusted.
That layer is what’s missing.
Information access is not the same as business understanding.
Why RAG breaks in analytics
Retrieval-augmented generation was supposed to fix context.
And for document-heavy use cases, it works well. If the task is to answer questions over policies, manuals, or support documentation, retrieving the most relevant chunks of text is often enough.
But analytics is different.
Traditional RAG is built on vector similarity — it finds things that sound similar to the question. Business analysis doesn’t work like that. It requires consistency, structure, and relationships.
If someone asks why profitability is dropping, the answer is not sitting in a paragraph somewhere. It depends on how revenue is defined, how costs are allocated, how customers are grouped, and how all of those elements interact over time.
You don’t need the AI to retrieve a similar paragraph. You need it to traverse a knowledge graph of your business.
That graph — whether explicit or implicit — is what allows the system to move from data to meaning.
Without it, RAG produces answers that are contextually relevant but operationally wrong.
The context layer is becoming the real moat
As models improve and become more accessible, the source of differentiation is shifting.
Not to intelligence — but to the environment around it.
Two companies can use the same model and get completely different outcomes. One produces reliable answers. The other produces confident nonsense.
The difference is not the model.
It is the context.
Better context can outperform better models when the task depends on business meaning.
The question companies should be asking is no longer “Which model should we use?”
It is:
What does our model need to know in order to understand our business?
What a Context Layer actually is
The context layer is the system that transforms raw data into structured business meaning that an AI agent can reliably reason over.
It is not just more data. It is a representation of how the business actually works.
In practice, that means encoding:
- Entities — customers, orders, products, campaigns, and how they exist across systems
- Metrics — how revenue, margin, retention, or LTV are actually defined
- Relationships — how those entities interact over time
- Trust — which sources are reliable and which are not
- Decisions — how answers should be interpreted and used
Without this layer, every query becomes a guess.
With it, the system starts to behave less like a query engine and more like an analyst.
Business context is what turns data into decisions.
A failure that looks like success
Imagine an eCommerce company asks:
“Which customers should we target to increase profitability?”
A powerful model runs the analysis. It identifies repeat customers, ranks them by revenue, and returns a clean, convincing answer.
Everything looks correct.
It isn’t.
The model ignored returns, discounts, shipping costs, and acquisition spend. The segment it recommends is actually destroying margin.
Nothing crashed. No error was thrown. The output is structured, readable, and actionable.
It’s also wrong.
The most dangerous failure mode is not incorrect answers. It’s plausible answers built on incorrect assumptions.
Context is also an economic advantage
There’s another dimension to this that most teams underestimate: cost.
When context is weak, systems compensate by doing more of everything. Larger prompts, more retrieval, bigger models, more retries.
That is expensive.
A strong context layer changes the equation.
| Scenario | Model Weight | Accuracy | Tokens / Cost |
|---|---|---|---|
| No Context | Frontier (GPT-4o) | ~65% | High (long prompts, retries) |
| With Context Layer | Mid-size (Llama 3) | ~95% | Low (precise, structured input) |
With better context, the model has less ambiguity to resolve. The problem becomes smaller. The reasoning becomes cheaper.
Context doesn’t just improve answers. It compresses the problem.
Why data agents are uniquely hard
Data agents expose this problem more than any other category.
Because in analytics, the gap between raw data and usable meaning is enormous.
The same customer appears under multiple IDs. The same metric is defined differently across teams. The same field changes meaning across systems. And most business questions are underspecified by default.
This is not a language problem.
It’s a semantic systems problem.
And that’s why the common stack — model + database + RAG + chat UI — rarely works as expected.
What’s missing is not intelligence.
It’s grounding.
What the future looks like
If this is the right frame, then the architecture of AI analytics changes.
At the center is the context layer.
Around it, everything else becomes modular:
- a reasoning layer (the model)
- an execution layer (SQL, APIs, pipelines)
The model becomes interchangeable. SQL becomes an implementation detail.
Context becomes the product.
The future is not better models. It’s better systems around them.
The real shift
Most companies are still shopping for intelligence.
They should be building context.
Because the real dividing line is simple:
Does your system understand the business — or is it just guessing?
The companies that win won’t have the smartest models. They’ll have the smartest context.
At Dataverto, we’re building the context layer for AI data agents — systems that understand your business, not just your schema. If you’re tired of answers that sound right but are wrong, let’s fix the layer that actually matters. Book a demo
FAQ
What is a context layer in AI?
A context layer is the system that transforms raw data into structured business meaning that an AI agent can reliably reason over. It includes entity definitions, metric logic, relationships between data points, and rules about which information is trustworthy.
Why do AI agents fail in data analysis?
AI agents fail in data analysis not because they lack intelligence, but because they lack business context. Without clear definitions, entity relationships, and trusted data sources, even advanced models can produce answers that are technically correct but business-wise wrong.
What is the difference between context and RAG?
RAG (retrieval-augmented generation) retrieves relevant documents based on similarity, while context defines how data should be interpreted. RAG helps the model find information, but a context layer ensures that the information is understood correctly within the business.
Why is context more important than the model?
Once models reach a certain level of capability, their performance depends more on the quality of the input than on raw intelligence. A well-structured context layer allows smaller models to outperform larger ones by reducing ambiguity and guiding reasoning.
How does a context layer reduce AI costs?
A context layer reduces costs by simplifying the reasoning process. With better context, models require fewer tokens, fewer retries, and can operate with smaller architectures. This leads to lower inference costs and faster responses.
What is the role of knowledge graphs in AI analytics?
Knowledge graphs help represent business entities and their relationships in a structured way. They allow AI agents to move beyond simple data retrieval and reason over how different parts of the business are connected.
Can you build reliable AI analytics without a context layer?
In most real-world scenarios, no. Without a context layer, AI systems rely on incomplete or ambiguous information, leading to unreliable outputs. This is especially true in complex environments like eCommerce, SaaS, or multi-source data systems.
What does “business context” mean in AI?
Business context refers to the definitions, rules, relationships, and constraints that determine how data should be interpreted in a specific company. It includes how metrics are calculated, which data sources are trusted, and how decisions should be made based on the data.